
구글 코랩(Colab)에서 특허데이터 크롤링 방법
연구 목적으로 특허 데이터를 추출할 수 있는 방법은 많습니다.
저는 그중에서 현재 진행하는 연구를 위해 Google Patents 웹사이트 데이터를 근간으로 추가 정보를 크롤링하여 데이터를 확보했는데요. 그 절차를 아래와 같이 공유합니다.
1. 대상 특허 확인
해당 사이트에서 원하는 특허 데이터를 키워드를 포함하여 다양한 옵션을 통해 검색합니다.
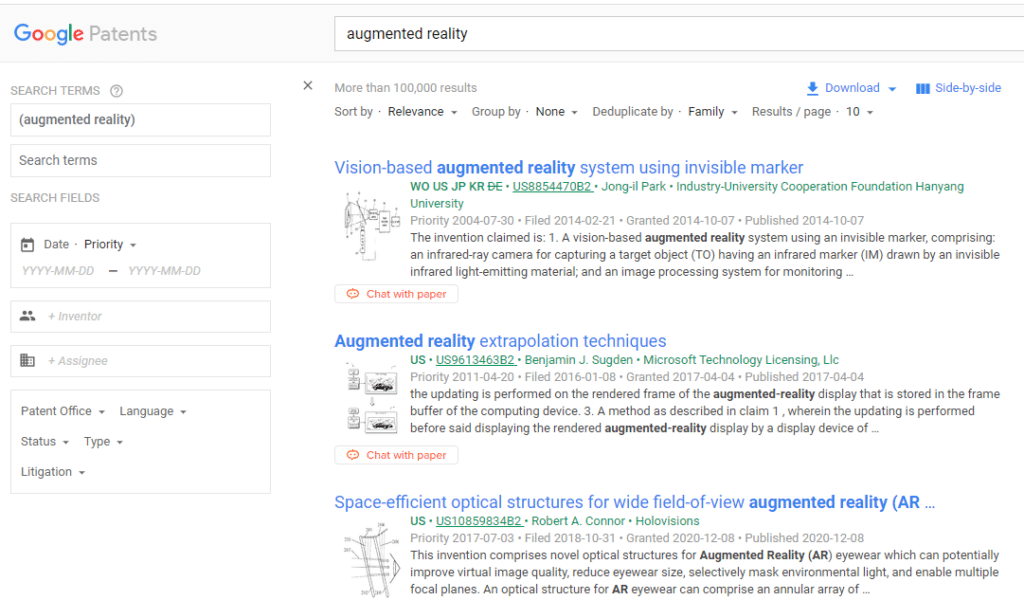
2. 특허 목록 다운로드
원하는 데이터를 검색했다면 아래 다운로드 버튼을 이용하여 csv 파일로 저장합니다.
데이터 양이 많아 전체 다운로드가 되지 않는다면, 검색조건을 분할하여 각각 내려받아야 합니다.

3. 특허 파일내 URL로 초록 크롤링
내려받은 파일을 열어보면 타이틀외 해당 특허를 확인할 수 있는 초록 등이 없기 때문에 result link 컬럼내 URL 정보를 확인했습니다.
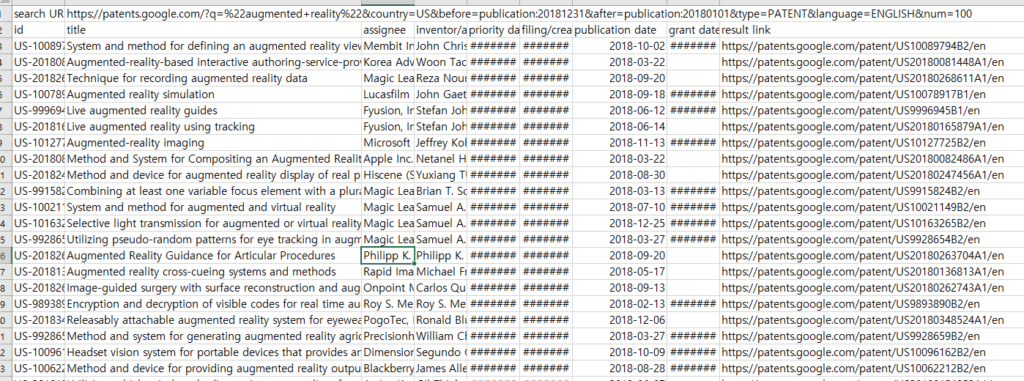
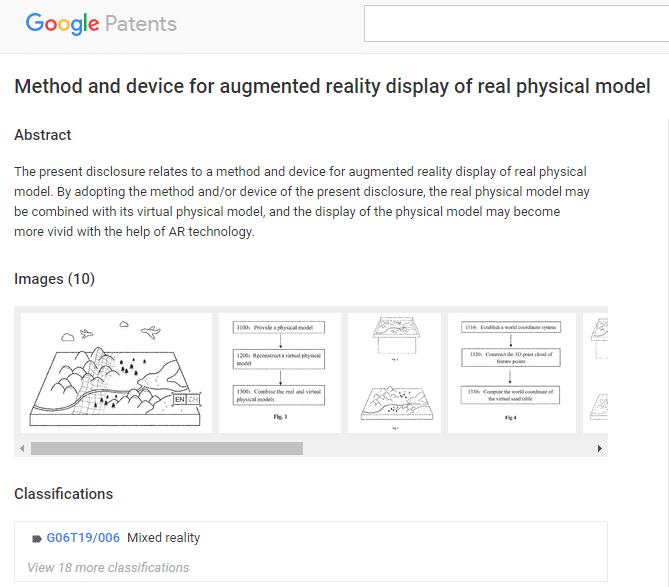
4. 특허 상세정보 확인
특정 특허의 URL 정보를 검색했더니, 아래와 같은 추가 데이터를 확인할 수 있습니다. 연구를 위해서는 아래 초록 데이터를 추가로 확보하는 것이 좋겠습니다.
5. 구글 코랩에서 사용 가능한 파이썬 크롤링 소스코드
특허 건수가 상당하기 때문에 파이썬 소스코드를 이용하여 초록 데이터를 크롤링했는데요. 크롤링 소스코드는 아래와 같습니다. (TQDM 적용)
# 특허초록 크롤링
from urllib.request import urlopen
from bs4 import BeautifulSoup
from tqdm.auto import tqdm, trange
from time import sleep
for i in trange(len(df)):
html = urlopen(df["result link"][i])
# 웹크롤링
bsObject = BeautifulSoup(html, "html.parser")
# 해외특허 Abstract 출력하기
try:
lv_abstract = bsObject.head.find("meta", {"name":"description"}).get('content')
except AttributeError:
continue
else:
# Abstract 데이터 컬럼 추가
df.loc[i, 'abstract'] = lv_abstract
sleep(0.01)6. 크롤링 오류 시, 해결방법
며칠 동안 위 소스코드를 이용하여 특허 초록 데이터를 수집했는데, 건수가 많아지다 보니 서버에서 오류를 리턴하여 자꾸 중단되는 상황이 발생하였습니다. 이를 해결하여 위해 아래와 같은 소스코드로 대체하여 모든 초록 데이터를 내려받았습니다.
# 크롤링 시 오류가 발생하여 예외처리 로직 추가
from urllib.request import urlopen, Request, HTTPError
from bs4 import BeautifulSoup
from tqdm.auto import tqdm, trange
from time import sleep
# User-Agent 설정
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
for i in trange(len(df)):
# Request 객체 생성
request = Request(df["result link"][i], headers=headers)
try:
html = urlopen(request)
except HTTPError as e:
print(f"HTTP error occurred for index {i}: {e}")
continue
# 웹크롤링O
bsObject = BeautifulSoup(html, "html.parser")
# 해외특허 Abstract 출력하기
try:
lv_abstract = bsObject.head.find("meta", {"name":"description"}).get('content')
except AttributeError:
continue
else:
# Abstract 데이터 컬럼 추가
df.loc[i, 'abstract'] = lv_abstract
sleep(0.01)이상으로 Google Patents 웹사이트에서 특허 데이터를 추출하는 방법을 설명하였고 문의사항은 댓글 남겨주시면 확인하고 답변 드리겠습니다.
